Big Data Arch
背景
行业案例
腾讯游戏大数据应用
- 大数据落地应用 = 数据 + 系统 + 算法 + 应用场景
- 腾讯游戏用户数据分层体系
- 腾讯游戏数据处理系统架构
饿了么数据仓库治理及数据应用
数据仓库的建设
标准化和规范化
统一日志搜集框架
原则
- 主题划分
- 数据一致性
- 维度建设
TODO
- 数据权限管理
- 数据使用记录
- 数据开放平台
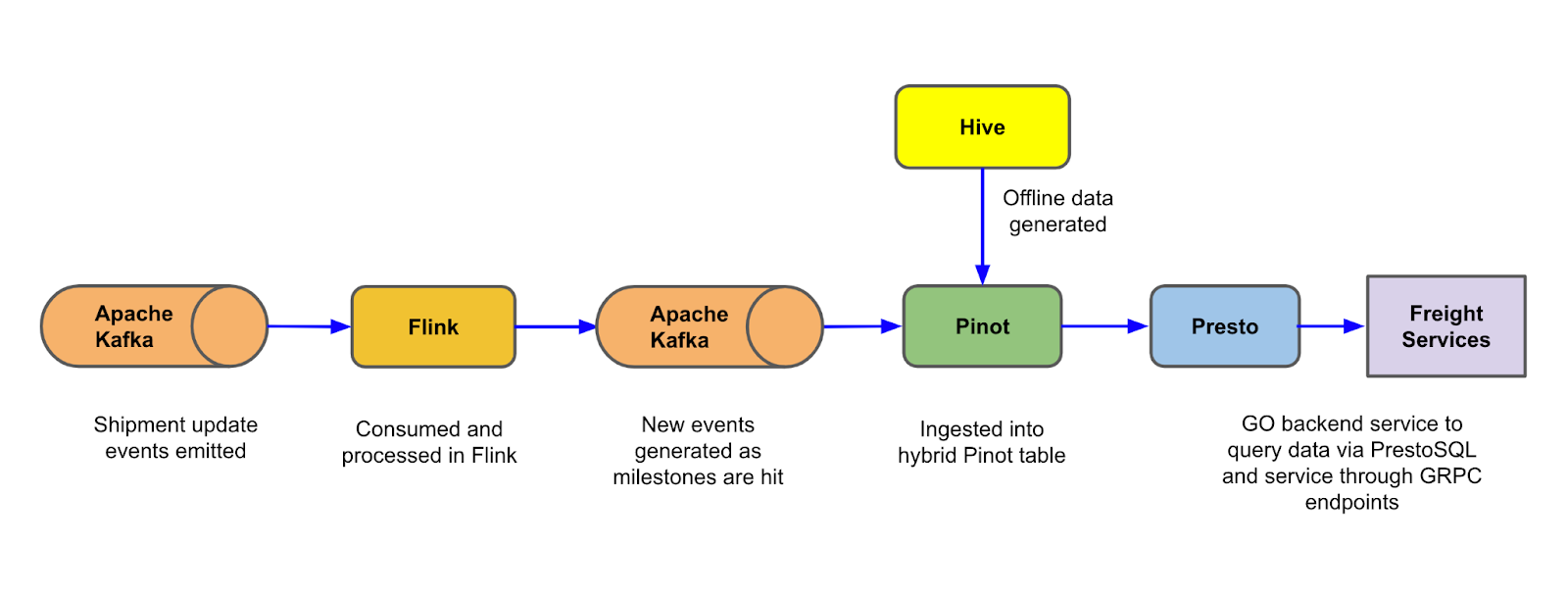
Uber Freight Carrier Metrics With Near-Real-Time Analytics
目录
- Introduction
- How We Did It
- Backend Requirement
- Potential Solution Considered
- Final System Design
- Data Schema
- Flink stateful Stream Process
- Hybrid Pinot Table
- Golang GRPC Service
- Impact
- Conclusion
通用方案
存储读取/写入
Data Lake 系列: 关于 EMRFS S3 优化的提交程序,你了解吗 文章与 FileOutputCommitter 进行了比较。
同时在 github repo s3committer 引出了 multi-part upload API 技术,可以用于处理大文件上传慢的问题。
但是对于小文件上传问题, 是否可以就并发上传就行了呢? No
方案: 压缩上传,上传完成后通过 AWS Lambda 来解压缩。 其中通过流(Stream)的方式解决 Only 500MB of disk space per instance 的限制[1],但执行时间有15分钟的限制,对于超大文件还是有。
参考
[1] John Paul Hayes: How to extract a HUGE zip file in an Amazon S3 bucket by using AWS Lambda and Python
最后修改
September 3, 2022
: add uber freight carrier system design (e664774)