模型推理架构
概念解释
Squared loss
a popular loss function, also known as L2 Loss.
Mean square error (MSE) is the average squared loss per example over the whole dataset.
Gradient Descent
SGD(Stochastic Gradient Descent) & Mini-Batch Gradient Descent.
Predict Protocol
This document proposes a predict/inference API independent of any specific ML/DL framework and model server.
This protocol is endorsed by NVIDIA Triton Inference Server, TensorFlow Serving, and ONNX Runtime Server.
Seldon has collaborated with the NVIDIA Triton Server Project and the KServe Project to create a new ML inference protocol. The core idea behind this joint effort is that this new protocol will become the standard inference protocol and will be used across multiple inference services.
详细见: [Predict Protocol - Version 2][2]
对标方案 - Run computer vision inference on large videos
Real-time Inference
Real-time inference is ideal for inference workloads where you have real-time, interactive, low latency requirements.
TensorRT through NVIDA Triton
TensorRT is a C++ library for high performance inference on NVIDIA GPUs and deep learning accelerators.
Tutorial: https://github.com/NVIDIA/TensorRT/blob/main/quickstart/SemanticSegmentation/tutorial-runtime.ipynb
- Load TensorRT Engine
- Run inference
TensorRT to Triton: https://github.com/NVIDIA/TensorRT/tree/main/quickstart/deploy_to_triton
Asynchronous inference
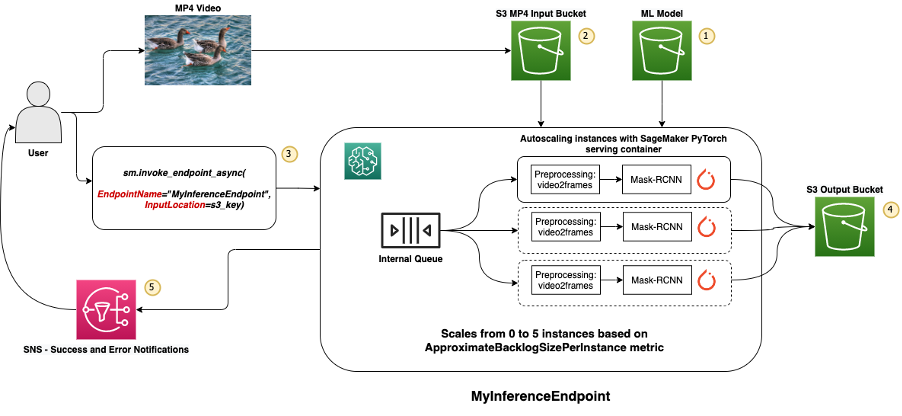
An Example for SageMaker: Amazon SageMaker Processing Video2frame Model Inference [3]

Prerequisites
实操方式: https://docs.aws.amazon.com/sagemaker/latest/dg/async-inference-create-endpoint-prerequisites.html
- Create an IAM role for Amazon SageMaker.
- Add Amazon SageMaker, Amazon S3 and Amazon SNS Permissions to your IAM Role.
- Upload your inference data (e.g., machine learning model, sample data) to Amazon S3.
- Select a prebuilt Docker inference image or create your own Inference Docker Image.
- Use Your Own Inference Code
- Create an Amazon SNS topic (optional)
- Check Your S3 Bucket: https://docs.aws.amazon.com/sagemaker/latest/dg/async-inference-check-predictions.html
Use Your Own Inference Code with Hosting Services
https://docs.aws.amazon.com/sagemaker/latest/dg/your-algorithms-inference-main.html,
how Amazon SageMaker interacts with a Docker container that runs your own inference code for hosting services.
How SageMaker Loads Your Model Artifacts
How Containers Serve Requests:
Containers need to implement a web server that responds to /invocations and /ping on port 8080.
How Your Container Should Respond to Inference Requests:
A customer’s model containers must respond to requests within 60 seconds.
Adapting Your Own Inference Container
https://docs.aws.amazon.com/sagemaker/latest/dg/adapt-inference-container.html
详细介好了基于 sagemaker 来自定义的推理过程。 https://sagemaker-examples.readthedocs.io/en/latest/frameworks/pytorch/get_started_mnist_deploy.html
Create
- Create a model in SageMaker with CreateModel.
- Create an endpoint configuration with CreateEndpointConfig.
- Create an HTTPS endpoint with CreateEndpoint.
Prebuilt SageMaker Docker Images for Deep Learning
https://docs.aws.amazon.com/sagemaker/latest/dg/pre-built-containers-frameworks-deep-learning.html
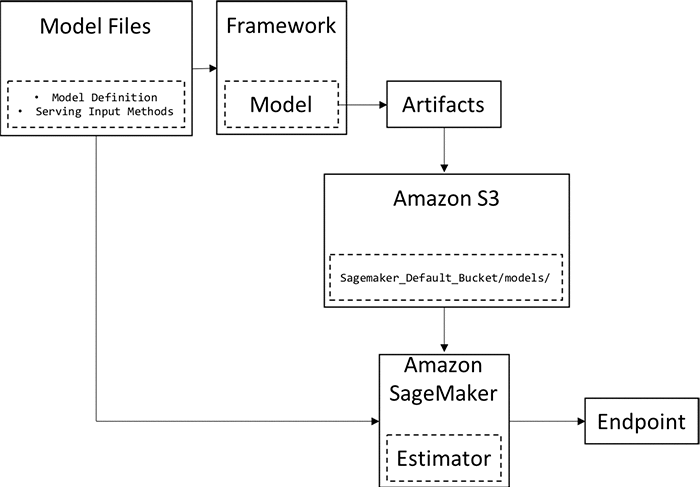
Entire process:
- Step 1: Model definitions are written in a framework of choice.
- Step 2: The model is trained in that framework.
- Step 3: The model is exported and model artifacts that can be understood by Amazon SageMaker are created.
- Step 4: Model artifacts are uploaded to an Amazon S3 bucket.
- Step 5: Using the model definitions, artifacts, and the Amazon SageMaker Python SDK, a SageMaker model is created.
- Step 6: The SageMaker model is deployed as an endpoint.
TensorFlow BYOM: https://github.com/aws/amazon-sagemaker-examples/blob/main/advanced_functionality/tensorflow_iris_byom
MXNet BYOM: https://github.com/aws/amazon-sagemaker-examples/tree/main/advanced_functionality/mxnet_mnist_byom
Batch Transform
Serverless Inference
Amazon SageMaker Serverless Inference is a purpose-built inference option that makes it easy for you to deploy and scale ML models. Serverless Inference is ideal for workloads which have idle periods between traffic spurts and can tolerate cold starts.
对标方案 - Machine Learning Platform for AI - EAS
- 一健部署
- 高性能
- 蓝绿部署
- 弹性扩缩
- 编译优化
参考
-
https://github.com/kserve/kserve/blob/master/docs/predict-api/v2/required_api.md#httprest
-
https://www.alibabacloud.com/help/zh/machine-learning-platform-for-ai/latest/architecture
-
Kubeflow: https://github.com/kubeflow
-
Amazon SageMaker Processing Video2frame Model Inference https://github.com/aws-samples/amazon-sagemaker-processing-video2frame-model-inference