Daily 0503
vCPU的解释
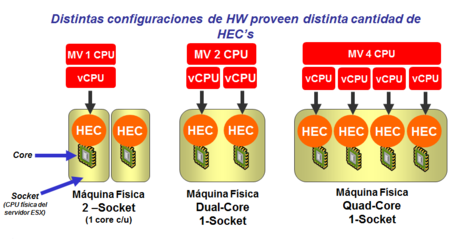
虛擬主機(Virtual Machine,VM)的CPU稱之為vCPU,當虛擬主機需要CPU運算資源的時候,VMkernel會將此虛擬主機需要的運算資源對應(Mapping)到實體伺服器的CPU核心運算HEC(Hardware Execution Context)能力,以使得虛擬主機得以進行運算。簡單來說,HEC就是實體伺服器的CPU核心數(Cores)。
所以,如圖5所示當虛擬主機配有1 vCPU,在需要運算資源時,只要VMkernel對應到實體主機上其中一個HEC就可以執行運算;若虛擬主機配有2 vCPU,在需要運算資源時,則必須對應到2個HEC才能運算;若4 vCPU則要對應4個HEC才能運算。
google python style guide
Python 是 Google主要的脚本语言。这本风格指南主要包含的是针对python的编程准则。
中文版Git
elk
更新license: Update License API
注册之后,可以使用xpack, 后台日志不会重复打
logstash_1 | [2018-05-03T11:31:00,614][INFO ][logstash.licensechecker.licensereader] Running health check to see if an Elasticsearch connection is working {:healthcheck_url=>http://logstash_system:xxxxxx@elasticsearch:9200/, :path=>"/"}
logstash_1 | [2018-05-03T11:31:00,615][WARN ][logstash.licensechecker.licensereader] Attempted to resurrect connection to dead ES instance, but got an error. {:url=>"http://logstash_system:xxxxxx@elasticsearch:9200/", :error_type=>LogStash::Outputs::ElasticSearch::HttpClient::Pool::BadResponseCodeError, :error=>"Got response code '401' contacting Elasticsearch at URL 'http://elasticsearch:9200/'"}
logstash_1 | [2018-05-03T11:31:03,796][INFO ][logstash.outputs.elasticsearch] Running health check to see if an Elasticsearch connection is working {:healthcheck_url=>http://logstash_system:xxxxxx@elasticsearch:9200/, :path=>"/"}
logstash_1 | [2018-05-03T11:31:03,797][WARN ][logstash.outputs.elasticsearch] Attempted to resurrect connection to dead ES instance, but got an error. {:url=>"http://logstash_system:xxxxxx@elasticsearch:9200/", :error_type=>LogStash::Outputs::ElasticSearch::HttpClient::Pool::BadResponseCodeError, :error=>"Got response code '401' contacting Elasticsearch at URL 'http://elasticsearch:9200/'"}
elastalert
docker elastalert
FROM python:2.7
WORKDIR /
RUN git clone https://github.com/Yelp/elastalert.git
RUN cd elastalert && git checkout v0.1.30 && pip install -r requirements.txt
WORKDIR /elastalert/
RUN ls -l
RUN apt-get install -y tzdata
ENV TZ Asia/Shanghai
CMD ["python", "elastalert/elastalert.py"]
参考文档:
Using ElastAlert
ElastAlert: Alerting At Scale With Elasticsearch 各种异常机制
index_not_found_exception 定位python报错行, 问题在于: elastalert判断elastsearch存在index,而实际上并不存在
github elastert isssue 1
解决办法:
create_index.py 244行注释掉delete函数
elasticsearch
some Elasticsearch terminology:
an Elasticsearch cluster is made up of one or more nodes. Each of these nodes contains indexes which are split into multiple shards. Elasticsearch makes copies of these shards called replicas. These (primary) shards and replicas are then placed on various nodes throughout the cluster.
更多内容
Elasticsearch 中写一致性原理以及quorum机制
[查看详情](Elasticsearch 中写一致性原理以及quorum机制)
Elasticsearch 5 docker 集群部署–单虚拟机多容器实例
实践
基于 《Elasticsearch: The Definitive Guide》的笔记
GET /my_index/_search
{
"query": {
"match_phrase": {
"names": "Lincoln Smith"
}
}
}
GET /_analyze
{
"analyzer": "standard",
"text": [
"John Abraham",
"Lincoln Smith"
]
}
GET /my_index/_doc/9
PUT /my_index/_doc/9
{
"names": ["John Abraham", "Lincoln Smith"]
}
GET /my_blog/_search
{
"query": {
"match_phrase": {
"body": "quick brown fox"
}
}
}
GET /my_blog/_search
{
"query": {
"dis_max": {
"queries": [
{
"match": {
"title": "Quick pets"
}
},
{
"match": {
"body": "Quick pets"
}
}
],
"tie_breaker": 0.7
}
}
}
GET /my_blog/_search
{
"query": {
"dis_max": {
"queries": [
{
"match": {
"title": "Brown fox"
}
},
{
"match": {
"body": "Brown fox"
}
}
]
}
}
}
# 返回了并不是用户想要的结果
GET /my_blog/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title": "Brown fox"
}
},
{
"match": {
"body": "Brown fox"
}
}
]
}
}
}
PUT /my_blog/_doc/2
{
"title": "Keeping pets healthy",
"body": "My quick brown fox eats rabbits on a regular basis."
}
PUT /my_blog/_doc/1
{
"title": "Quick brown rabbits",
"body": "Brown rabbits are commonly seen."
}
PUT /my_blog
GET /my_index/_search
{
"query": {
"match": {
"title": {
"query": "BROWN DOG",
"operator": "and"
}
}
}
}
GET /my_index/_search
{
"query": {
"match": {
"title": "QUICK!"
}
}
}
POST /my_index/_bulk
{ "index": { "_id": 1 }}
{ "title": "The quick brown fox" }
{ "index": { "_id": 2 }}
{ "title": "The quick brown fox jumps over the lazy dog" }
{ "index": { "_id": 3 }}
{ "title": "The quick brown fox jumps over the quick dog" }
{ "index": { "_id": 4 }}
{ "title": "Brown fox brown dog" }
# 为什么 shard 为 1
PUT /my_index
{
"settings": {
"number_of_shards": 1
}
}
DELETE /my_index
GET /my_store/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"productID": "KDKE-B-9947-#kL5"
}
},
{
"bool": {
"must": [
{
"term": {
"price": "30"
}
},
{
"term": {
"productID": {
"value": "JODL-X-1937-#pV7"
}
}
}
]
}
}
]
}
}
}
DELETE /my_store
GET /my_store/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"term": {
"productID": "XHDK-A-1293-#fJ3"
}
}
]
}
}
}
PUT /my_store
{
"mappings" : {
"properties" : {
"productID" : {
"type" : "keyword"
}
}
}
}
POST /my_store/_doc/_bulk
{ "index": { "_id": 1 }}
{ "price" : 10, "productID" : "XHDK-A-1293-#fJ3" }
{ "index": { "_id": 2 }}
{ "price" : 20, "productID" : "KDKE-B-9947-#kL5" }
{ "index": { "_id": 3 }}
{ "price" : 30, "productID" : "JODL-X-1937-#pV7" }
{ "index": { "_id": 4 }}
{ "price" : 30, "productID" : "QQPX-R-3956-#aD8" }
GET /us-tweet/_search
{
"query": {
"match_all": {}
}
, "_source": ["tweet", "date"]
}
GET /us-tweet
GET /us-tweet/_search?search_type=dfs_query_then_fetch
# explain API to understand why one particular document matched or, more important, why it didn't match .
GET /us-tweet/_doc/12/_explain
{
"query": {
"bool": {
"filter": {
"term": {
"user_id": "3"
}
},
"must":
{
"match": {
"tweet": "honeymoon"
}
}
}
}
}
GET /_search?explain=true
{
"query": {
"match": {
"tweet": "honeymoon"
}
}
}
GET /_search
{
"query": {
"bool": {
"must": { "match": {
"tweet": "managee text search"
}
},
"filter": [
{ "term": {
"user_id": "2"
}
}
]
}
}
}
GET /us-tweet/_search
{
"query": {
"bool": {
"filter": {
"term": {
"user_id": 1
}
}
}
},
"sort": {
"date": {
"order": "desc"
}
}
}
GET /_search
PUT /us-user
PUT /gb-user
PUT /gb-tweet
PUT /us-tweet
POST /_bulk
{"create":{"_index":"us-user","_id":"1"}}
{"email":"john@smith.com","name":"John Smith","username":"@john"}
{"create":{"_index":"gb-user","_id":"2"}}
{"email":"mary@jones.com","name":"Mary Jones","username":"@mary"}
{"create":{"_index":"gb-tweet","_id":"3"}}
{"date":"2014-09-13","name":"Mary Jones","tweet":"Elasticsearch means full text search has never been so easy","user_id":2}
{"create":{"_index":"us-tweet","_id":"4"}}
{"date":"2014-09-14","name":"John Smith","tweet":"@mary it is not just text, it does everything","user_id":1}
{"create":{"_index":"gb-tweet","_id":"5"}}
{"date":"2014-09-15","name":"Mary Jones","tweet":"However did I manage before Elasticsearch?","user_id":2}
{"create":{"_index":"us-tweet","_id":"6"}}
{"date":"2014-09-16","name":"John Smith","tweet":"The Elasticsearch API is really easy to use","user_id":1}
{"create":{"_index":"gb-tweet","_id":"7"}}
{"date":"2014-09-17","name":"Mary Jones","tweet":"The Query DSL is really powerful and flexible","user_id":2}
{"create":{"_index":"us-tweet","_id":"8"}}
{"date":"2014-09-18","name":"John Smith","user_id":1}
{"create":{"_index":"gb-tweet","_id":"9"}}
{"date":"2014-09-19","name":"Mary Jones","tweet":"Geo-location aggregations are really cool","user_id":2}
{"create":{"_index":"us-tweet","_id":"10"}}
{"date":"2014-09-20","name":"John Smith","tweet":"Elasticsearch surely is one of the hottest new NoSQL products","user_id":1}
{"create":{"_index":"gb-tweet","_id":"11"}}
{"date":"2014-09-21","name":"Mary Jones","tweet":"Elasticsearch is built for the cloud, easy to scale","user_id":2}
{"create":{"_index":"us-tweet","_id":"12"}}
{"date":"2014-09-22","name":"John Smith","tweet":"Elasticsearch and I have left the honeymoon stage, and I still love her.","user_id":1}
{"create":{"_index":"gb-tweet","_id":"13"}}
{"date":"2014-09-23","name":"Mary Jones","tweet":"So yes, I am an Elasticsearch fanboy","user_id":2}
{"create":{"_index":"us-tweet","_id":"14"}}
{"date":"2014-09-24","name":"John Smith","tweet":"How many more cheesy tweets do I have to write?","user_id":1}
# Don't Repeat Yourself
# 出错,从 7.0 开始,一个索引下一个类型
POST /website/_bulk
{ "index": {"_type": "blog" } }
{ "title": "User logged in" }
GET /website/
# 不要其他的元数据
GET /website/blog/123/_source
# 检索文档的一部分
GET /website/blog/123?_source=title,text
GET /website/blog/123?pretty
POST /website/blog/
{
"title": "My second Blog entry" ,
"text": "still tying this out .... ",
"date": "2014/01/02"
}
PUT /website/blog/123
{
"title": "My First Blog entry" ,
"text": "just tying this out .... ",
"date": "2014/01/01"
}
PUT /website
GET _search
{
"query": {
"match_all": {}
}
}
PUT /megacorp
PUT /megacorp/employee/1
{ "first_name" : "John", "last_name" : "Smith", "age" : 25, "about" : "I love to go rock climbing", "interests": [ "sports", "music" ]
}
PUT /megacorp/employee/2
{ "first_name" : "Jane", "last_name" : "Smith", "age" : 32, "about" : "I like to collect rock albums", "interests": [ "music" ] }
PUT /megacorp/employee/3
{ "first_name" : "Douglas", "last_name" : "Fir", "age" : 35, "about": "I like to build cabinets", "interests": [ "forestry" ] }
GET /megacorp/employee/1
GET /megacorp/employee/_search
GET /megacorp/employee/_search?q=last_name:Smith
# DSL 查询
GET /megacorp/employee/_search
{
"query": {
"match": {
"last_name": "Smitch"
}
}
}
# 年龄大于30岁的员工。
GET /megacorp/employee/_search
{
"query": {
"bool":{
"filter": {
"range": {
"age": { "gt": 30 }
}
},
"must": {
"match": {
"last_name": "smitch"
}
}
}
}
}
GET /megacorp/employee/_search
{
"query": {
"match": {
"about": "rock climbing"
}
}
}
GET /megacorp/employee/_search
{
"query": {
"match_phrase": {
"about": "rock climbing"
}
}
}
# 因为我要聚合的字段 「interests」没有进行优化,也类似没有加索引
# 没有优化的字段 es 默认是禁止聚合/排序操作的。
PUT /megacorp/_mapping?pretty
{
"properties": {
"interests": {
"type": "text",
"fielddata": true
}
}
}
# 让我们找到所有职员中最大的共同点是什么?
GET /megacorp/employee/_search
{
"aggs":{
"all_interests": {
"terms": {"field": "interests" }
}
}
}
GET /megacorp/employee/_search
{
"query": {
"match": {
"last_name": "smith"
}
},
"aggs": {
"all_interests": {
"terms": {
"field": "interests"
}
}
}
}
GET /megacorp/employee/_search
{
"aggs": {
"all_interests": {
"terms": {
"field": "interests"
},
"aggs": {
"avg_age": {
"avg": {"field": "age"}
}
}
}
}
}
PUT /blogs
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}
GET /_cluster/health
nginx配置
(location =) > (location 完整路径) > (location ^~ 路径) > (location ~,~* 正则顺序) > (location 部分起始路径) > (/)
更多详情
tornado
sqlalchemy 和 tornado的结合: session管理放在了每次的request的请求中处理为最佳,以及每次请求经来时,实例化session, 请求结束后, 将session关闭
scoped_session session 注册表,从中取用和还取,并保证多次取用的为统一session
此处的sqlalchemy的数据库查询,并不是异步,当使用tornado 的异步特性时,遇到查询数据库慢时,还是会阻塞的,此时我们更多的需要考虑的
handle blocking tasks in Tornado
其中Ben Darnell回复的,
A ThreadPoolExecutor is the recommended way to use blocking functions that cannot be easily rewritten as non-blocking. When you call
yield self._exe(n), that handler will be suspended and the main thread will return to the HTTPServer so it is free to handle other requests. The suspended handler will wake up when the task is completed and the IOLoop is not busy. The new thread pool is created by the main thread but is not “in” the thread. Thread pools should generally be either global or class variables; not instance variables. It is a good practice to have one thread pool for each kind of resource: e.g. one thread pool for database queries and second pool for image processing. This lets you set and monitor separate limits for each one.
import tornado.web
from tornado.concurrent import run_on_executor
from concurrent.futures import ThreadPoolExecutor
import time
class MainHandler(tornado.web.RequestHandler):
def get(self):
self.write("Hello, world %s" % time.time())
class SleepHandler(tornado.web.RequestHandler):
@property
def executor(self):
return self.application.executor
@tornado.gen.coroutine
def get(self, n):
n = yield self._exe(n)
self.write("Awake! %s" % time.time())
self.finish()
@run_on_executor
def _exe(self, n):
"""
This is a long time job and may block the server,such as a complex DB query or Http request.
"""
time.sleep(float(n))
return n
class App(tornado.web.Application):
def __init__(self):
handlers = [
(r"/", MainHandler),
(r"/sleep/(\d+)", SleepHandler),
]
tornado.web.Application.__init__(self, handlers)
self.executor = ThreadPoolExecutor(max_workers=60)
if __name__ == "__main__":
application = App()
application.listen(8888)
tornado.ioloop.IOLoop.instance().start()
python
MD,最喜欢的还是贴好文章的链接
PYTHON中YIELD的解释: 这个代码解释详细了,什么是“鸭子类型" (duck typing)
再来一个链接: Iterables vs. Iterators vs. Generators 原来generators还有两种类型(Type): generator functions and generator expressions
这真是一个很长的story啊
futrue使用
Futrue模式的主要使用场景: 当前线程需要依赖另一线程的返回数据并且处理数据的线程又相当耗时,那么Futrue模式就可以使主线程提交数据请求给另一线程处理业务逻辑,等需要时将另一线程返回,很好的利用了等待时间
Python concurrent.future 使用教程及源码初剖
yield 协程
yield并没有指定当前进程要将执行权利移交给谁,只是放弃运行权利,至于下面由谁来运行,完全看进程调度schedule();多用于I/O等待时,进程短暂wait,但是并没有退出运行队列。
进程管理之yield
[ Yield 和 Coroutine ] (http://wsfdl.com/python/2016/11/13/yield_and_croutine.html)
Python (at least in the CPython implementation) has a Global Interpreter Lock which prevents multiple threads from executing Python code at the same time. In particular, anything which runs in a single Python opcode is uninterruptible unless it calls a C function which explicitly releases the GIL. A large exponentation with ** holds the GIL the whole time and thus blocks all other python threads, while a call to bcrypt() will release the GIL so other threads can continue to work.
深入理解 GIL:如何写出高性能及线程安全的 Python 代码 介绍了GIL
参考
[1] Clinton Gormley and Zachary Tong: Elasticsearch: The Definitive Guide